![]()
All-in-one AI framework



![]()

txtai is an all-in-one AI framework for semantic search, LLM orchestration and language model workflows.

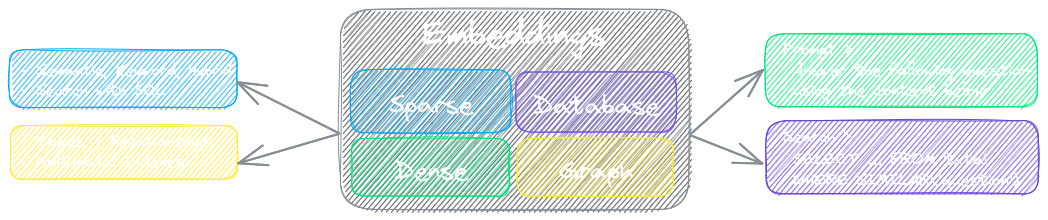
The key component of txtai is an embeddings database, which is a union of vector indexes (sparse and dense), graph networks and relational databases.
This foundation enables vector search and/or serves as a powerful knowledge source for large language model (LLM) applications.
Build autonomous agents, retrieval augmented generation (RAG) processes, multi-model workflows and more.
Summary of txtai features:
- 🔎 Vector search with SQL, object storage, topic modeling, graph analysis and multimodal indexing
- 📄 Create embeddings for text, documents, audio, images and video
- 💡 Pipelines powered by language models that run LLM prompts, question-answering, labeling, transcription, translation, summarization and more
- ↪️️ Workflows to join pipelines together and aggregate business logic. txtai processes can be simple microservices or multi-model workflows.
- 🤖 Agents that intelligently connect embeddings, pipelines, workflows and other agents together to autonomously solve complex problems
- ⚙️ Web and Model Context Protocol (MCP) APIs. Bindings available for JavaScript, Java, Rust and Go.
- 🔋 Batteries included with defaults to get up and running fast
- ☁️ Run local or scale out with container orchestration
txtai is built with Python 3.10+, Hugging Face Transformers, Sentence Transformers and FastAPI. txtai is open-source under an Apache 2.0 license.
Note
NeuML is the company behind txtai and we provide AI consulting services around our stack. Schedule a meeting or send a message to learn more.
We're also building an easy and secure way to run hosted txtai applications with txtai.cloud.