Index guide
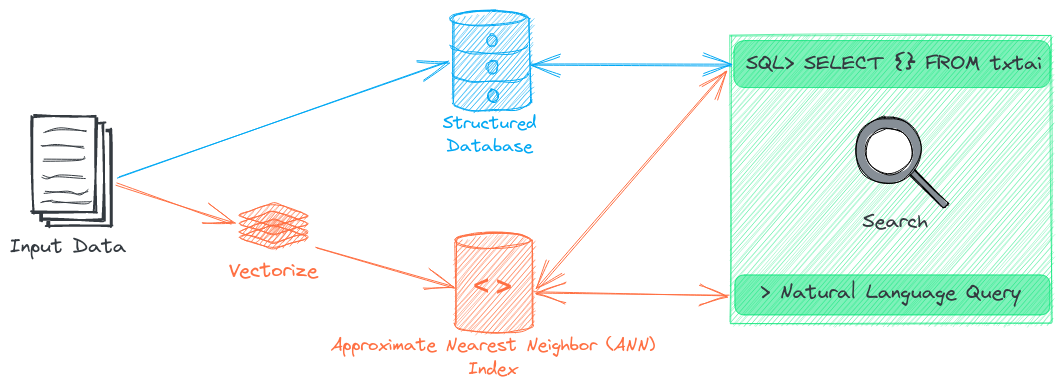
This section gives an in-depth overview on how to index data with txtai. We'll cover vectorization, indexing/updating/deleting data and the various components of an embeddings database.
Vectorization
The most compute intensive step in building an index is vectorization. The path parameter sets the path to the vector model. There is logic to automatically detect the vector model method but it can also be set directly.
The batch and encodebatch parameters control the vectorization process. Larger values for batch will pass larger batches to the vectorization method. Larger values for encodebatch will pass larger batches for each vector encode call. In the case of GPU vector models, larger values will consume more GPU memory.
Data is buffered to temporary storage during indexing as embeddings vectors can be quite large (for example 768 dimensions of float32 is 768 * 4 = 3072 bytes per vector). Once vectorization is complete, a mmapped array is created with all vectors for Approximate Nearest Neighbor (ANN) indexing.
The terms ANN and dense vector index are used interchangeably throughout txtai's documentation.
Setting a backend
As mentioned above, computed vectors are stored in an ANN. There are various index backends that can be configured. Faiss is the default backend.
Content storage
Embeddings indexes can optionally store content. When this is enabled, the input content is saved in a database alongside the computed vectors. This enables filtering on additional fields and content retrieval.
The columns used for text, object and JSON data storage are set via column configuration.
Index vs Upsert
Data is loaded into an index with either an index or upsert call.
embeddings.index([(uid, text, None) for uid, text in enumerate(data)])
embeddings.upsert([(uid, text, None) for uid, text in enumerate(data)])
The index call will build a brand new index replacing an existing one. upsert will insert or update records. upsert ops do not require a full index rebuild.
Save
Indexes can be stored in a directory using the save method.
embeddings.save("/path/to/save")
Compressed indexes are also supported.
embeddings.save("/path/to/save/index.tar.gz")
In addition to saving indexes locally, they can also be persisted to cloud storage.
embeddings.save("/path/to/save/index.tar.gz", cloud={...})
This is especially useful when running in a serverless context or otherwise running on temporary compute. Cloud storage is only supported with compressed indexes.
Embeddings indexes can be restored using the load method.
embeddings.load("/path/to/load")
Delete
Content can be removed from the index with the delete method. This method takes a list of ids to delete.
embeddings.delete(ids)
Reindex
When content storage is enabled, reindex can be called to rebuild the index with new settings. For example, the backend can be switched from faiss to hnsw or the vector model can be updated. This prevents having to go back to the original raw data.
embeddings.reindex(path="sentence-transformers/all-MiniLM-L6-v2", backend="hnsw")
Graph
Enabling a graph network adds a semantic graph at index time as data is being vectorized. Vector embeddings are used to automatically create relationships in the graph. Relationships can also be manually specified at index time.
# Manual relationships by id
embeddings.index([{"id": "0", "text": "...", "relationships": ["2"]}])
# Manual relationships with additional edge attributes
embeddings.index(["id": "0", "text": "...", "relationships": [
{"id": "2", "type": "MEMBER_OF"}
]])
Additionally, graphs can be used for topic modeling. Dimensionality reduction with UMAP combined with HDBSCAN is a popular topic modeling method found in a number of libraries. txtai takes a different approach using community detection algorithms to build topic clusters.
This approach has the advantage of only having to vectorize data once. It also has the advantage of better topic precision given there isn't a dimensionality reduction operation (UMAP). Semantic graph examples are shown below.
Get a mapping of discovered topics to associated ids.
embeddings.graph.topics
Show the most central nodes in the index.
embeddings.graph.centrality()
Graphs are persisted alongside an embeddings index. Each save and load will also save and load the graph.
Sparse vectors
Scoring instances can create a standalone sparse keyword indexes (BM25, TF-IDF) and sparse vector indexes (SPLADE). This enables hybrid search when there is an available dense vector index.
The terms sparse vector index, keyword index, terms index and scoring index are used interchangeably throughout txtai's documentation.
See this link to learn more.
Subindexes
An embeddings instance can optionally have associated subindexes, which are also embeddings databases. This enables indexing additional fields, vector models and much more.
Word vectors
When using word vector backed models with scoring set, a separate call is required before calling index as follows:
embeddings.score(rows)
embeddings.index(rows)
Both calls are required to support generator-backed iteration of data with word vectors models.